
Automatizar parte do contas a pagar com IA já é possível — e não apenas para ganhar produtividade, mas para reduzir erros operacionais e trabalho manual no financeiro.
Tem uma ideia que virou senso comum: que IA serve pra ganhar produtividade. Melhorar a redação de um e-mail, resumir um relatório, escrever um post. Útil, mas pequeno. O que quase não se vê é que ela já resolve problemas reais, daqueles que reduzem erro e trabalho de verdade dentro da operação.
E a chave pra chegar nesse nível não é assistir a mais um vídeo sobre prompts perfeitos. É começar por um problema real, com dados reais. É exatamente o que temos feito aqui na Treasy. E hoje trago um exemplo real de um incômodo antigo do nosso próprio financeiro: o lançamento manual do contas a pagar.
O resultado foi uma automação que entrou em produção em menos de dois dias (na prática, em duas "janelas de conversa" com o Claude Code). Mas, mais importante que a velocidade, foi o que esse projeto pode ensinar sobre colocar a IA pra trabalhar de verdade. É sobre as duas coisas que quero falar aqui: a automação em si e o método por trás dela.
Os prompts para você criar essa mesma automação na sua empresa estão neste material.
- Fatia 1: Entender o que chega no e-mail
- Fatia 2: Extrair os dados dos documentos
- Fatia 3: Uma planilha viva que sugere fornecedor, categoria, centro de custo e data de competência
O problema real (e por que ele é mais comum do que parece)
A gente recebe cobranças de fornecedores num e-mail dedicado, ex: contasapagar@suaempresa.com.br. O processo era o de sempre, e provavelmente o mesmo do seu financeiro: abrir o e-mail, abrir o PDF anexo, copiar valor, vencimento e data de competência, e lançar no ERP (no nosso caso, o Granatum) com a categoria e o centro de custo corretos. Repetir. E repetir de novo.
Repare que já aqui tem detalhes que costumam ser negligenciados: a competência certa, a categoria certa, o centro de custo certo. Não é só "jogar o valor" no ERP, é classificar bem, senão a informação não serve pra análise depois.
Três problemas nesse fluxo:
- É repetitivo: o tipo de tarefa que cansa e que ninguém quer fazer.
- É sujeito a erro: valor digitado errado, vencimento ou competência trocados, categoria ou centro de custo equivocados.
- E errar aqui custa caro e/ou prejudica a análise e a tomada de decisão: não é só um lançamento errado num campo: é uma decisão tomada em cima de um número que não bate com a realidade.
A pergunta que guiou o projeto, então, não foi pequena: quanto do contas a pagar, de ponta a ponta, eu consigo automatizar, sem nunca delegar o pagamento em si para uma IA? O que vou contar aqui é a primeira etapa desse caminho, que você pode replicar na sua empresa (vou deixar um link com os prompts).
A decisão que veio antes do código: modo sombra
Antes de escrever uma única linha, eu estabeleci um princípio inegociável:
A IA propõe e explica. O código determinístico verifica. Um humano aprova no final.
Na prática, isso virou o que chamei de modo sombra. Por 30 dias, o sistema só lê e sugere. Nada é lançado no ERP automaticamente (ainda, mas o céu é o limite). Todos os dias a automação coloca as cobranças que encontrou numa planilha no Google Sheets, com a sugestão de fornecedor, categoria e centro de custo (sugeridos com base no histórico de 90 dias de lançamentos do ERP), já no formato exato em que seriam enviados pro ERP num próximo passo. Eu confiro, corrijo o que estiver errado, e cada correção realimenta as sugestões dos dias seguintes.
Por que tanto cuidado? Porque o custo do erro é assimétrico. Deixar uma cobrança pra eu conferir (um "falso negativo") me custa alguns minutos. Lançar um valor errado de forma automática (um "falso positivo") pode custar muito mais, uma conta paga com valor errado, um fornecedor pago em duplicidade, uma análise comprometida. A automação inteira foi pensada pra refletir essa assimetria.
A confiança numa automação financeira não pode ser um pressuposto de quem esta criando a automação. É uma coisa que se mede com dados reais ao longo do tempo. O modo sombra é exatamente o período em que você coleta esses dados antes de comprometer qualquer coisa.
É como se você estivesse treinando um estagiário com capacidades cognitivas absurdas 🙂
Como foi construído: em fatias verificáveis
Eu não tentei resolver tudo de uma vez só. Quebrei o trabalho em fatias pequenas, cada uma com um resultado que eu conseguia conferir antes de avançar. Esse, aliás, foi um dos grandes aprendizados (volto nele mais pra frente).
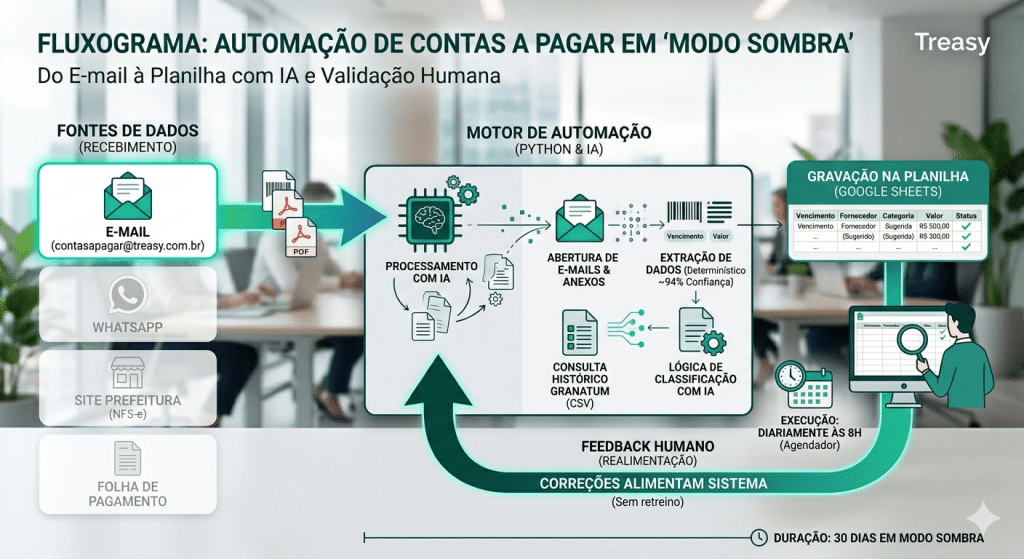
Fatia 1: Entender o que chega no e-mail
Antes de extrair qualquer coisa, precisei entender o que de fato cai naquela caixa de e-mail. Analisamos 90 dias de e-mails: 28 cobranças reais, 42 e-mails internos, 15 ruídos e 5 ambíguos.
(Repare que mesmo com um processo estruturado, muita cobrança coisa não vai parar na caixa de e-mail).
E aqui vieram os primeiros aprendizados que só aparecem quando você olha o dado de verdade:
- Um dos fornecedores manda 2 ou 3 lembretes do mesmo boleto. Sem deduplicação, eu lançaria a mesma conta várias vezes.
- Uma das notas chega em duplicidade: pelo aviso da prefeitura e pelo encaminhamento da contabilidade.
- Alguns e-mails de cobrança vêm sem anexo nenhum (o valor está no corpo da mensagem).
Nenhuma dessas situações estava no meu "plano mental" do problema. Elas só apareceram porque comecei pelos dados reais, não por uma ideia de como o problema deveria funcionar.
Tenho certeza que você vai encontrar várias situações assim aí na sua empresa.
Fatia 2: Extrair os dados dos documentos
Aqui vem uma decisão que talvez surpreenda: a extração foi 100% determinística. Sem IA.
Montei três camadas, em ordem de confiança:
- Linha digitável do boleto: valor e vencimento estão codificados ali de forma aritmética, e dá pra validar com o dígito verificador (mod-10). Confiança de quase 100%.
- Regex com contexto de rótulo: busca por marcações como "Vencimento:", "Total:", "Data de repasse:". Cerca de 80% de confiança.
- Layout de NFS-e padrão nacional (DANFSe): onde o rótulo está numa linha e o valor na seguinte.
Por que não usar IA na extração? Porque o código determinístico já entregava 94% de acerto. E aí ficou clara uma regra que adotei pro projeto inteiro: a IA só entra onde o determinístico não chega aos 95%. Ela não é a solução padrão; é a ferramenta pro problema que o método mais simples e barato não resolve.
Os números dessa fatia: 30 PDFs processados, 16 cobranças consolidadas, 94% com valor extraído corretamente. E mais uma descoberta no caminho: os "anexos" de um dos fornecedores eram, na verdade, pixels de rastreamento do e-mail, não PDFs. O boleto estava como imagem no corpo do e-mail o tempo todo.
Fatia 3: Uma planilha viva que sugere fornecedor, categoria, centro de custo e data de competência
A última fatia transformou os dados extraídos em algo útil pra quem confere. Cada cobrança chega na planilha com uma sugestão de fornecedor, categoria e centro de custo (sugeridos com base no histórico do ERP), montada com uma ordem de precedência bem clara:
- Feedback humano (as correções feitas na planilha) — ganha de tudo.
- Histórico do Granatum (os lançamentos reais que já existem).
- Vazio — fornecedor novo, classificar na mão.
Na primeira carga: 18 cobranças, 17 com sugestão de confiança alta, média ou baixa. Tudo rodando sozinho com o agendador do Windows, todo dia às 8h.
E um trabalho manual a menos para o financeiro 🙂

O que os números mostram: escopo honesto vale mais que cobertura total
Depois de rodar, fiz um cruzamento com todos os lançamentos reais do ERP no período. A pergunta era: quanto das cobranças a fonte "e-mail" realmente enxerga?
A resposta foi reveladora. A fonte e-mail cobre cerca de 31% do valor das despesas endereçáveis, mas só uns 2% da contagem. Ou seja: poucas contas, porém as de maior tíquete.
E o que nunca vai aparecer no e-mail? Cartão de crédito, folha de pagamento, impostos, plano de saúde etc.
Isso poderia parecer uma falha do projeto, mas não é. É uma escolha consciente de escopo. E o aprendizado é que saber exatamente o que fica de fora é mais valioso do que uma automação que "tenta cobrir tudo" e falha em silêncio.
O que aprendemos sobre usar IA em automação financeira
Vou deixar cinco princípios que não podem faltar quando você estiver criando suas soluções de IA para problemas reais do seu financeiro:
- Comece sempre pelo modo sombra. Você precisa de dados reais pra calibrar a confiança antes de qualquer comprometimento.
- Determinístico primeiro, IA depois. A IA entra onde o método simples não chega — não como solução automática pra tudo.
- O feedback humano é dado, não validação. Cada correção alimenta a próxima sugestão, sem retreino e sem código novo.
- Escopo honesto é mais útil que cobertura total. Saber o que fica de fora é parte do trabalho.
- O custo do erro é assimétrico. No contas a pagar, por exemplo, errar pra dentro do sistema é muito mais caro que deixar pro humano. O design tem que refletir isso.
Tão importante quanto a automação: aprender a trabalhar com a IA
Se eu tivesse que escolher o que mais levo desses projetos, não seria a automações em si. Seria o que aprendemos sobre trabalhar com os recursos da IA (no nosso caso, o Claude).
Construir algo nesse nível de completude e nessa velocidade dá trabalho real; não foi mágica. O que fez diferença não foi a ferramenta sozinha, foi o método de trabalhar junto com ela e ter processos claros no financeiro da empresa. Algumas dicas importantes:
Comece com um problema real, não com um exercício. A IA aprende junto com você durante o projeto. A qualidade do que ela entrega no fim depende muito da qualidade do problema que você trouxe no início. Problema vago gera solução genérica. Problema real, com dados reais, gera solução que funciona pro seu caso.
A precisão melhora com validação (exatamente como acontece com uma pessoa). Quanto mais eu confirmava o que estava certo e corrigia o que estava errado, mais afiado ficava o próximo passo. Num momento do projeto, quando voltamos a analisar os e-mails, o Claude já tinha processado o histórico do Granatum e usou esse contexto pra classificar melhor as categorias. Foi o mesmo mecanismo de um colaborador que vai ficando mais afiado conforme entende mais do seu negócio. A IA não "sabia" do meu financeiro no começo — ela foi aprendendo a minha operação no meio do caminho, da mesma forma que um analista novo aprenderia.
Peça coaching de uso à própria IA durante o projeto. Em determinado momento, perguntei ao Claude como eu poderia ter trabalhado melhor com ele até ali. A resposta foi específica, útil e ainda deu tempo de aplicar, porque eu perguntei no meio, não no fim.
E a vantagem que quase ninguém menciona: é feito pra você. Uma solução genérica de mercado cobre 80% dos casos de todo mundo. Uma solução construída com IA pro seu problema cobre 95% do seu caso — com a lógica da sua operação, seus fornecedores, suas regras, seu ERP. O nível de personalização é absurdo pro custo. E a manutenção é barata, porque o código é legível e eu entendi cada decisão enquanto ela era tomada.
É por isso que insisto em começar por um problema real. Não dá pra desenvolver essa habilidade (saber o que pedir, como validar, quando confiar) usando a IA só pra coisas corriqueiras. É o problema real, com dados reais e consequências reais, que te obriga a aprender de verdade. E é também onde a IA mostra que já resolve muito mais do que tarefas pequenas.
Espero que este guia seja útil para você, e não deixe de compartilhar com a gente se você rodar essa automação aí na sua empresa! E se tiver dificuldade no processo, vamos conversar.





Deixe um comentário
Você precisa estar logado para postar um comentário. Clique aqui para fazer o login